Utiliser l’outil le mieux adapté à une tâche est primordial, dans le monde réel comme dans le monde numérique. Il est possible de faire communiquer des outils numériques, spécialisés dans certaines tâches, grâce à la technologie headless.
- Headless
-
En anglais, headless signifie « sans tête ». Le terme est utilisé pour désigner un outil numérique capable de renvoyer des données brutes sans se charger de leur affichage.
La technologie headless permet de construire un site internet ou une application mobile en utilisant des données distantes fournies par d’autres outils, qui peuvent être codés dans différents langages de programmation, être hébergés sur des serveurs différents ou appartenir à d’autres sociétés.
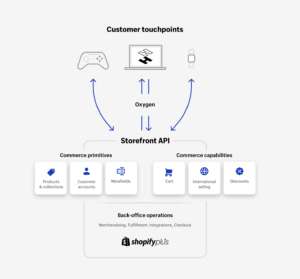
L’idée est de ne pas réinventer la roue en profitant des meilleurs outils existants, chacun étant spécialisé dans une tâche précise.
On peut citer quelques exemples d’outils très connus proposant un mode headless :
- WordPress pour la gestion de contenu éditorial,
- Shopify pour la gestion d’un site e-commerce,
- Indeed pour la gestion d’offres d’emploi,
- Discourse pour la gestion d’un forum,
- Twitter ou Facebook pour la gestion d’une communauté, etc.
Imaginons qu’un client nous commande la réalisation d’un site web avec à la fois des fonctionnalités sur mesure (calcul de devis, espace membre, etc.) et une section « blog » tout à fait classique.
Pour le développement sur mesure, nous allons partir de zéro avec un framework adapté, comme Ruby on Rails ou Laravel.
Pour le blog, nous n’allons pas coder de zéro un CMS (Content Management System) entier, avec la gestion du contenu en back-office, des catégories, des images, des auteurs, des rôles, etc. Nous allons créer un deuxième site sur lequel nous installerons un WordPress configuré en mode headless, c’est à dire qu’il sera utilisé pour saisir et stocker les articles, mais pas pour les afficher.
Nous coderons ensuite dans le premier site une page qui appellera le site WordPress pour lui demander les articles en mode headless, et celui-ci renverra les données sous une forme brute que nous mettrons en forme.
L’utilisation de la technologie headless peut s’envisager dans deux sens :
- soit nous devons appeler un outil en mode headless pour récupérer des données,
- soit nous devons rendre un outil que nous développons capable de répondre en mode headless.
Pour récupérer des informations depuis un outil distant, celui-ci doit proposer une interface headless. Pour reprendre l’exemple de WordPress, celui-ci inclut nativement une API (Application Programming Interface ou Interface de Programmation) que nous pouvons appeler pour avoir la liste des derniers articles, les articles d’une catégorie, un article complet, etc.
Une API est un ensemble de points d’entrée, ici des URL, qui vont renvoyer des données sous forme brute (au format JSON par exemple) et non pas du HTML comme une URL de site classique.
Voyons ce que renvoie l’API de WordPress si nous voulons obtenir le contenu brut de l’article que vous êtes en train de lire. L’URL à appeler est la suivante (vous pouvez l’ouvrir dans votre navigateur) :
https://www.imagile.fr/wp-json/wp/v2/posts/8431
Voici le début de la réponse :

Ce charabia n’est pas fait pour être lu par un humain, mais sera facile à interpréter par un autre outil qui se chargera de l’afficher.
Remarquez que l’URL de l’API ne nécessite pas d’authentification, les données de ce blog étant publiques. Il est tout à fait possible de restreindre la consultation d’une URL d’API en imposant la présence d’un token d’identification dans la requête.

Lorsque nous développons des sites ou des webapps, il nous est souvent demandé de les rendre capables de répondre en mode headless, afin qu’ils puissent être interrogés à distance par tout autre outil ayant besoin des données brutes.
Les frameworks que nous utilisons ont déjà cette fonctionnalité, nativement ou via un plugin, elle est donc simple et rapide à mettre en place.
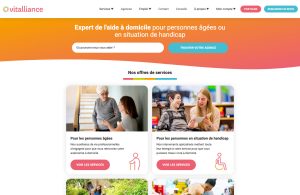
Le site de Vitalliance, spécialiste de l’aide à domicile, est principalement un outil de génération de leads. Il est développé sur mesure en Ruby on Rails par nos soins, sauf pour la partie Actualités, qui elles viennent d’un autre site, non public, sur lequel nous avons installé un WordPress.
Nous avons donc fait l’économie du back-office de gestion des actualités, ce que WordPress fait déjà très bien.
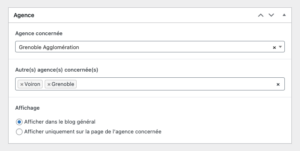
De plus, comme une actualité peut concerner une ou plusieurs agences Vitalliance, le WordPress appelle le site principal en mode headless pour récupérer la liste des agences et la rendre disponible en back-office.
D’autre part, Vitalliance développe une application mobile pour se connecter à son espace client. Cette appli appelle le site vitalliance.fr en mode headless pour récupérer les informations sur les agences et leurs équipes. Les données restent à un seul endroit, et Vitalliance n’a pas eu besoin de développer un autre back-office en interne pour gérer ces données spécialement pour l’appli.
On pourrait opposer à l’utilisation d’outils headless la nécessité d’avoir dans l’équipe technique plus de compétences pour maîtriser les différents outils mobilisés. Dans notre cas, nous maîtrisons en interne plusieurs langages, plusieurs frameworks et les stacks techniques associées, nous pouvons donc avec confiance utiliser des outils hétérogènes, mais il est compréhensible que cela fasse peur à une équipe plus petite ou moins expérimentée.
Nous opposons à cet argument le besoin de compétences encore plus grand et plus varié s’il fallait développer un CMS ou un e-commerce de zéro.
Si l’outil appelé en mode headless ne nous appartient pas (Shopify, Twitter, etc.), nous avons par définition moins de contrôle sur lui. Nous sommes dépendants de la société propriétaire en ce qui concerne :
- la correction de bugs,
- le choix des prochaines fonctionnalités,
- la disponibilité et la stabilité du serveur,
- la sécurité des données échangées,
- la politique tarifaire.
Il est donc important de benchmarker les différentes solutions du marché pour faire un choix éclairé, et d’évaluer les conséquences d’un arrêt du service (panne, hausse des tarifs, faillite, etc.) en regardant le niveau de dépendance à ce service. Il est prudent de prévoir un comportement par défaut en cas de panne du service pour impacter le moins possible le business du client.
Dernière précaution à prendre avant de faire le choix d’un outil headless : la performance. Puisque les outils communiquent entre eux à distance, le temps de réponse est forcément plus long que si les données venaient de la base de données locale. La mesure de ce temps de réponse est important pour guider la stratégie à mettre en place : améliorer le serveur, mettre en cache les données renvoyées pendant une certaine durée, etc.